


three models of scalable deliberation with LLMs
realizing the dream of One Big Meeting without actually having to attend one

Ancient theorists - indeed, pretty much through the early modern period with Montesquieu and Rousseau - were in agreement that democracy was scale-limited, feasible only at the level of a city-state. After all, you’d need everybody to attend one big meeting!
Modern electoral democracy doesn’t depend on everybody attending one big meeting. You vote for a party, parties represent some set of ideological stances with hopefully meaningful distinctions, parties send people to meetings with subcomittees and so on. This is because it’s expensive to have everybody talk to one another. But it also lends itself to institutional capture.
Here are three ways LLMs could virtually facilitate arbitarily-large meetings where everyone “attends.” None of these solve the issues of mediation that already exist, but they have them in different ways, and could allow democratic organizations (parties, states, firms, fraternal organization, whatever) to scale more efficiently.
Polis
Pol.is is an already-existing tech produced by the Computational Democracy Project. For a breakdown of how it works, you can read the whitepaper here1 (this post should in some ways just be read as an advert for the whitepaper) or watch this very uncanny valley AI-generated video:
Briefly, Polis gathers responses to a question and clusters them, letting people see how they cluster and responding in real time. In a sense it can be seen as a kind of forum technology that differs, and potentially scales better, than linear or branching forum threads.
The creepy video mentions the possibility of off-topic or inappropriate comments as a potential downside, and moderation tools as a means to prevent this; one might just as easily reverse that and say moderation power is a problem - but the level of power handed to mods clearly isn’t essential to the technology.
An additional concern is that giving respondents an accurate map before they develop their own thoughts more than one iteration out can lead to groupthink. (Of course, people may have intuitive senses about where the group consensus lies, and an accurate model may be less dangerous in many ways than an inaccurate one.)
mediated equilibration
I’m pretty sure this could be implemented right now with custom GPTs, though for higher-stakes stuff you’d want a good open-source model.2 It’s an attempt to reduce the groupthink worries and the difference between more and less articulate individuals, but runs risks of ceding more power to the LLM mediator itself.
In this model, everyone is asked to summarize their thoughts, and the data and arguments they find compelling, into some text document. An LLM is given access to the conjoined text files (along with, perhaps, some additional files of agreed-upon data, or dueling sources of contested data.)

The LLM then gives back a summary of different considerations. These are clustered, in the sense that redundant considerations are folded together, but no information is conveyed about how common those considerations are.3 The LLM will attempt as charitable a summary as it can of each consideration, tailoring it to the preferred technical level of each individual audience, who can ask clarifying questions.
People then are able to offer any additional responses and changes to mind. They can then repeat this process until some cycle limit is met, or until there are no new considerations or changes of mind present.

Once this has stopped, the LLM summarizes and clusters opinions, providing data to everyone on where the shape of consensus lies - only at this point does anyone know (more than they did before) what ideas are popular. They can then go through the normal process of decision-making.
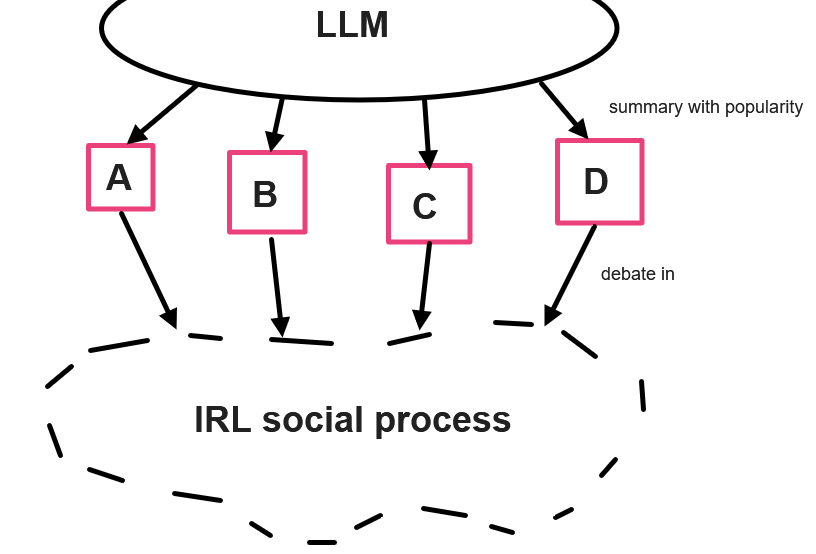
Obviously there is no “correct” cycle limit (up to full equilibration), just the usual speed/accuracy tradeoff that exists in deliberation of any kind.
send your homunculus to the dollhouse of commons
Here’s the weirdest and the most mediated. In its breadth and speed, but probably low trustworthiness, it may work best as a supplementation to other methods. It’s also less immediately implementable.

In this model, you create a bot version of you with RLHF and text access to your worldview, experiences, things you care about, and so on. You can aim for accurate representation of yourself or an idealized-deliberator version, or whatever. My guess is that once this is technically feasible, people will invent versions of this purely for the novelty aspect, and so it should be easy to adopt from there.4
In this version, all the bots talk to each other, and consult agreed-upon sources of relevant data, until there are no new updates to the bots’ positions. In its pure form, the computational cost of this should scale exponentially with the size of the group; one might have some degree of sortition, of SGD-like sampling, or random selection of who talks to whom, in order to make the computational costs feasible. However, computation should be getting cheaper and cheaper.
The logical limit of this is simply to have whole brain emulations of everyone deliberate in One Big Meeting. In that case you do kind of have to attend the meeting, but if WBEs enter the picture everything then enough other things are changed that much of this is obsolete.
I discovered this paper, and via it Polis, after thinking about the second proposal in this post and searching “scalable deliberation” to see if anybody was using this phrase for anything. The fact that they were using it for basically the same thing I take as a sign from God this is the correct approach.
I agree that high-quality open-source LLMs are probably too dual-use to exist. That said, the default timeline is that they will anyway!
The number of non-redundant considerations should scale monotonically with, but slower than, the size of the group. (A convenient approximation if we wanted one without empirical data would be the natural log.)
Indeed, this already exists; it’s just not very good. A bigger concern is that if we can accomplish this - human-scale reasoning at arbitrarily fast speeds - we’re basically already in a foom scenario and humanity is fucked. There may be levels of this - perhaps even stable ones with the right regulatory framework - that are smart enough to work, but too stupid to kill us.
These seem like interesting methods for simulating public discourse and achieving communicative rationality at some level. Its not just a wisdom of crowds, but offers a feedback mechanism that would guide the end result towards some reasonable equilibrium.
But does this become less effective the more technical and obscure the issue is? Are there empirical/conceptual barriers to this democratic form of decision making, which may be better left to experts in the field with the requisite background and evidence on hand? Moreover, you may have expected that social media and widespread communication would at least have moved others towards a more reasonable viewpoint, but on many issues, some have become more extreme in the face of feedback. Could LLM-led discourse similarly create "less" rational positions, despite expectations otherwise?